神经元再利用假说视角下,AI辅助阅读的系统性方法论
2019年,我第一次尝试用AI工具辅助阅读。那时的工具还很简陋,输出内容空洞得让人失望。五年后的今天,AI已经能生成看似专业的书摘和拆解,但我逐渐意识到一个核心问题:这些工具在放大人类阅读的认知缺陷,而非弥补它们。
阅读脑机制的三个硬件级缺陷
现代神经科学的核心发现是「神经元再利用假说」——人类大脑并没有进化出专门的阅读模块,而是强行调用视觉皮层、布洛卡区、运动皮层,外加后天训练的视觉词形区,凑出一套阅读功能。这套「拼装系统」天然存在三个硬件级bug。
第一个bug是框架依赖性。海马体的编码逻辑遵循「关联优先」原则:没有预先建立的认知框架,新接收的信息会变成零散碎片,难以整合成有效记忆。这解释了为什么传统的「先粗读后细读」方法经久不衰。
第二个bug是线性处理的局限性。眼球物理运动决定了阅读是严格线性的——一个字接一个字、一行接一行。但知识密集型著作的内在结构往往是网状的:A概念理解需要B和C作为前提,而B又指向D。用线性扫描去捕获网状结构,认知负荷极高,回溯成本巨大。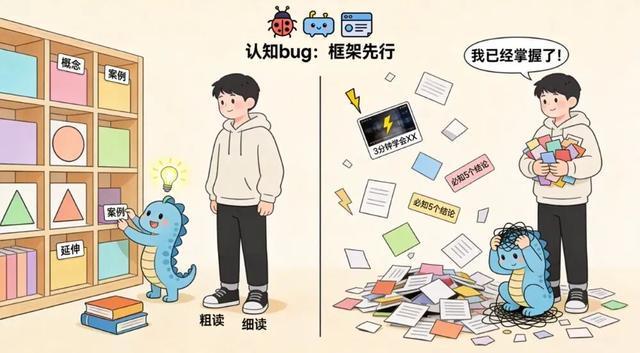
第三个bug是前置信息差的隐蔽性。优质书籍通常预设读者具备某些基础知识,缺失这些背景会导致理解偏差甚至完全读不懂。快餐式拆书会进一步加剧这个问题——跳过铺垫和推导过程后,结论变成了悬空的断言,失去支撑它的背景网络。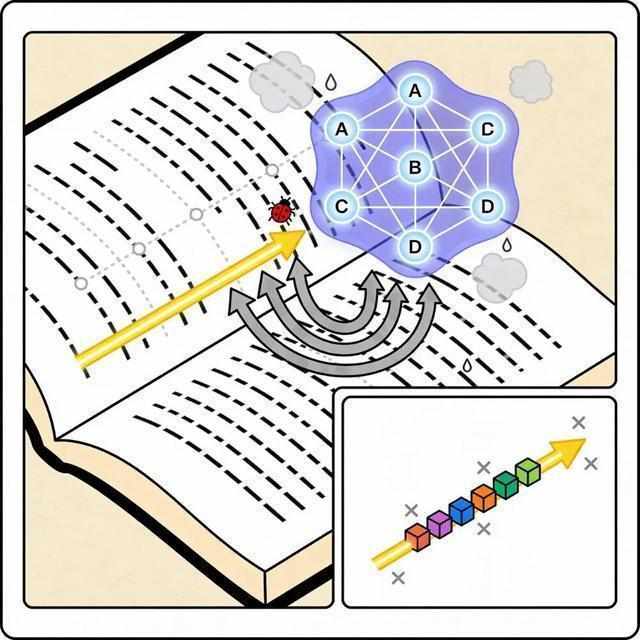
AI工具的双刃剑效应
功利性阅读要求内容准确、细节扎实、可落地执行。快餐拆书为了适配大众、追求流量,只能输出粗颗粒度内容,核心的实践细节被大量裁剪。更严重的是,二次加工必然带来信息偏差和意图偏离。
消遣性阅读的核心价值在于沉浸式情绪体验。小说的铺垫、转折、细腻描写,散文中的闲笔和幽默彩蛋,都是构成「心流」体验的必要元素。拆书把这些细节全部滤除,只剩下干巴巴的结论,情绪价值归零。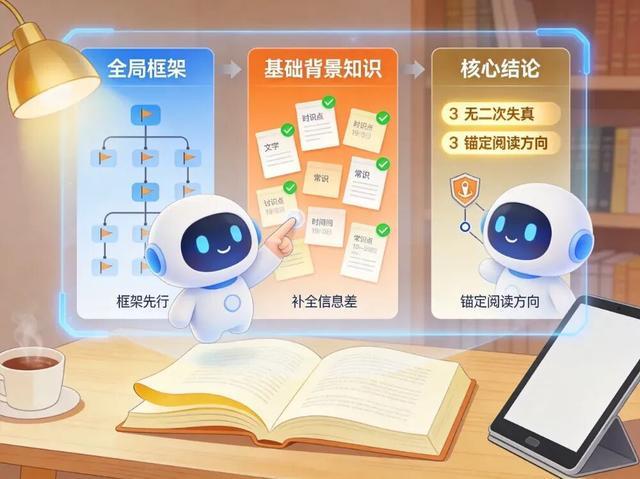
AI辅助阅读的正确打开方式
正确的做法是将AI定位为认知脚手架搭建工具,而非内容替代品。第一步,在正式阅读前让AI输出三个核心内容:全书全局框架(建立认知锚点)、必要基础背景知识(消除前置信息差)、原作者核心结论(锚定阅读方向)。
第二步,阅读后的深度加工。主动提问验证理解深度,而非简单复述;进行知识缝合,将新概念与已有知识体系连接;激发进一步探索,基于书中遗留问题追踪最新研究进展。这种方式才能真正把阅读转化为长期记忆和可迁移能力。
